Why Evaluating AI Agents Matters Now
The Case for an Agent Trust Infrastructure
Abstract
Organizations are deploying AI agents at speed — for customer service, code generation, data analysis, compliance workflows. But the honest answer to "how do I know if this agent is good enough?" remains: nobody really knows. This article examines the structural gap between model-level evaluation and the agent-level trust infrastructure that production deployments require. Drawing on emerging research in standardized AI evaluation and operational maturity frameworks, we argue that evaluation is not a post-deployment concern — it is the foundation on which trustworthy agent deployment is built, and the reason we open-sourced AgentFit.
1.The Deployment Moment
Something unusual is happening in enterprise software right now. Organizations are moving AI agents from experimentation into production at a pace that far outstrips the evaluation and governance infrastructure around them. Customer support agents resolve billing disputes. Coding agents submit pull requests. Compliance agents flag regulatory risk. Data analysis agents synthesize board reports. Each of these is an AI system operating with real consequences and limited human oversight — and most were deployed without a structured answer to the question: is this agent actually ready?
This is a recognizable pattern in software history. New paradigms consistently outrun the testing and reliability tooling they need. Distributed systems arrived before we had good practices for distributed tracing. Microservices arrived before we had mature service mesh and observability tooling. The pattern is not a failure of foresight — it is the natural consequence of adoption moving faster than infrastructure.
But the stakes with AI agents are structurally different. A distributed system that fails produces a timeout or an error. An agent that fails may execute incorrect API calls, consume resources, send messages on someone's behalf, or make decisions that are difficult to reverse. The cost of an undetected failure in an agentic system is often not just technical — it is operational, legal, and reputational.
The question "does this agent work?" is no longer sufficient. The question organizations need to answer is: "Is this agent trustworthy enough to operate autonomously in this specific context — and can I demonstrate that to the people who depend on that judgment?"
2.Models Are Not Agents
Before you can design evaluation infrastructure for AI agents, you need to understand what makes them categorically different from the models that power them. The distinction matters enormously, and it is one the evaluation community has been slow to formalize.
A language model is a function: given a sequence of input tokens, produce a probability distribution over output tokens. Its evaluation is correspondingly tractable — you can measure accuracy, perplexity, alignment, and reasoning on curated benchmarks. MMLU, HumanEval, HELM, BIG-Bench — these are well-understood instruments for measuring what a model knows and can reason about in isolation.
An agent is something different. It perceives an environment, selects and calls tools, takes sequences of actions, and pursues goals across multiple turns. It doesn't just produce outputs — it produces effects in systems that extend far beyond the model itself. The LLM is the reasoning core; the agent is the system built around it.
Ali El Filali and Inès Bedar make this distinction rigorously in their paper Towards More Standardized AI Evaluation: From Models to Agents1. They observe that the evaluation community has built sophisticated infrastructure for model-level assessment but has not yet achieved the same standardization for agentic systems — systems defined by their capacity for tool use, multi-step reasoning, environmental interaction, and autonomous decision-making.
"The transition from evaluating models to evaluating agents introduces new dimensions of complexity: agents operate across extended task horizons, interact with external environments, and must exhibit behaviors — such as appropriate escalation and tool selection — that have no direct analogue in static benchmark evaluation."
— El Filali & Bedar, 2025
Their framework identifies several key gaps that benchmark-centric evaluation leaves unaddressed. Model benchmarks assess capability on isolated, curated tasks; agent evaluation requires assessing behavior across task sequences with real or simulated tool calls. Model evaluation is largely provider-specific; agent evaluation needs to cross organizational and framework boundaries to be meaningful. Model performance is relatively stable across runs; agent behavior can be non-deterministic and path-dependent in ways that single-shot benchmarks entirely miss.1
The implication is significant: you cannot extrapolate agent fitness from model capability scores. An agent running on GPT-4o may perform worse on your specific production workflow than one running on a smaller, fine-tuned model — because what matters is how the model behaves as an agent in your specific context, not how it ranks on an abstract leaderboard.
3.The Evaluation Gap in Practice
The current landscape for AI agent evaluation falls into three broad approaches, each with significant limitations for production deployment decisions.
Benchmark suites — SWE-Bench, AgentBench, WebArena, τ-Bench — provide standardized task accuracy on curated scenarios. They are excellent for tracking capability at the model and framework level, and represent genuine scientific progress. But they don't answer "is this agent fit for my specific billing workflow, in my compliance environment, at my required latency?" They measure against someone else's definition of a well-formed task, not yours.
Framework-native evaluation — OpenAI Evals, LangSmith, PromptFlow — provides tight feedback loops within a specific ecosystem. Useful for iterative development, but structurally vendor-locked. They can't easily compare behavior across providers, and they don't model the organizational context that makes an agent fit or unfit for a specific deployment.
Manual review and vibe-checks remain the most common approach in practice. Teams run the agent through representative scenarios and use judgment to decide if it's ready. This is unscalable, inconsistent across reviewers, and produces no audit trail — which becomes a governance and compliance problem as agents take on more consequential tasks. It is also, fundamentally, not evaluation. It is intuition. Intuition is valuable; it is not sufficient.
None of these approaches answers the central question: Is this agent fit for my specific business context — and can I explain why?
4.Trust as a Structural Property
"Trust" is used loosely in discussions of AI safety and alignment. For the purposes of deployment decisions — where someone's business outcomes depend on an agent's behavior — it is worth being more precise.
In organizational contexts, trust in a system or agent is built on three structural properties. Predictability: the system behaves consistently with its documented behavior across situations. Explainability: the basis for the system's decisions can be understood and reviewed by people who depend on them. Accountability: when the system fails, the failure can be attributed, understood, and corrected.
None of these properties are inherent in any language model or framework. They are constructed through the evaluation and observability infrastructure built around the model. A model without evaluation infrastructure is like a new hire with no references, no structured onboarding, and no role specification — you might trust them, but you're doing it on faith.
Trust in an AI agent, therefore, is not a property of the agent itself. It is a property of the relationship between the agent and the evaluation infrastructure that surrounds it. Organizations that skip that infrastructure are not just taking a technical risk — they are making a governance decision by omission.
5.Operational Trust Maturity for Autonomous Systems
A useful lens for thinking about where organizations stand — and where they need to get to — comes from operational maturity frameworks like CMMI (Capability Maturity Model Integration)2, which describes how organizations progress from ad hoc, heroic individual effort to systematized, measured, and continuously improving processes.
Applied to AI agent deployment, four levels of operational trust maturity are visible across the organizations we've worked with:
Agent Trust Maturity Model
Agent behavior is evaluated informally, if at all. Teams rely on developer intuition and manual testing. There is no consistent definition of "fit for deployment." Failures are discovered in production.
Teams have defined evaluation criteria and run agents through representative scenarios before deployment. Results are documented but not reproducible, and not comparable across teams or agent versions.
Evaluation is anchored to explicit business requirements. Dimensions are weighted according to the deployment context. Results are reproducible and auditable. Scores can be compared across agent versions and providers. This is the minimum viable standard for production deployment.
Evaluation feeds into continuous monitoring. Agents are re-evaluated as their environment changes. Trust is maintained through ongoing observability and automated re-assessment, not just pre-deployment checks.
Most organizations deploying AI agents today are operating at Level 1 or early Level 2. The industry needs the tooling and frameworks to make Level 3 the baseline norm — and to provide a clear path to Level 4 for teams deploying agents in high-stakes or regulated environments.
6.Observability as a Trust Primitive
Observability in software systems refers to the degree to which the internal state of a system can be inferred from its external outputs. Logging, distributed tracing, and metrics are the three classic primitives. The OpenTelemetry standard3 has done significant work to standardize how these are collected and correlated across complex, distributed architectures.
For AI agents, there is a fourth pillar: evaluation. Knowing that an agent called a tool is useful — a log event. Knowing whether that tool call was the right one, made in the right way, with the right parameters, at the right point in a task sequence — that requires an evaluation layer that captures behavioral signal, not just operational signal.
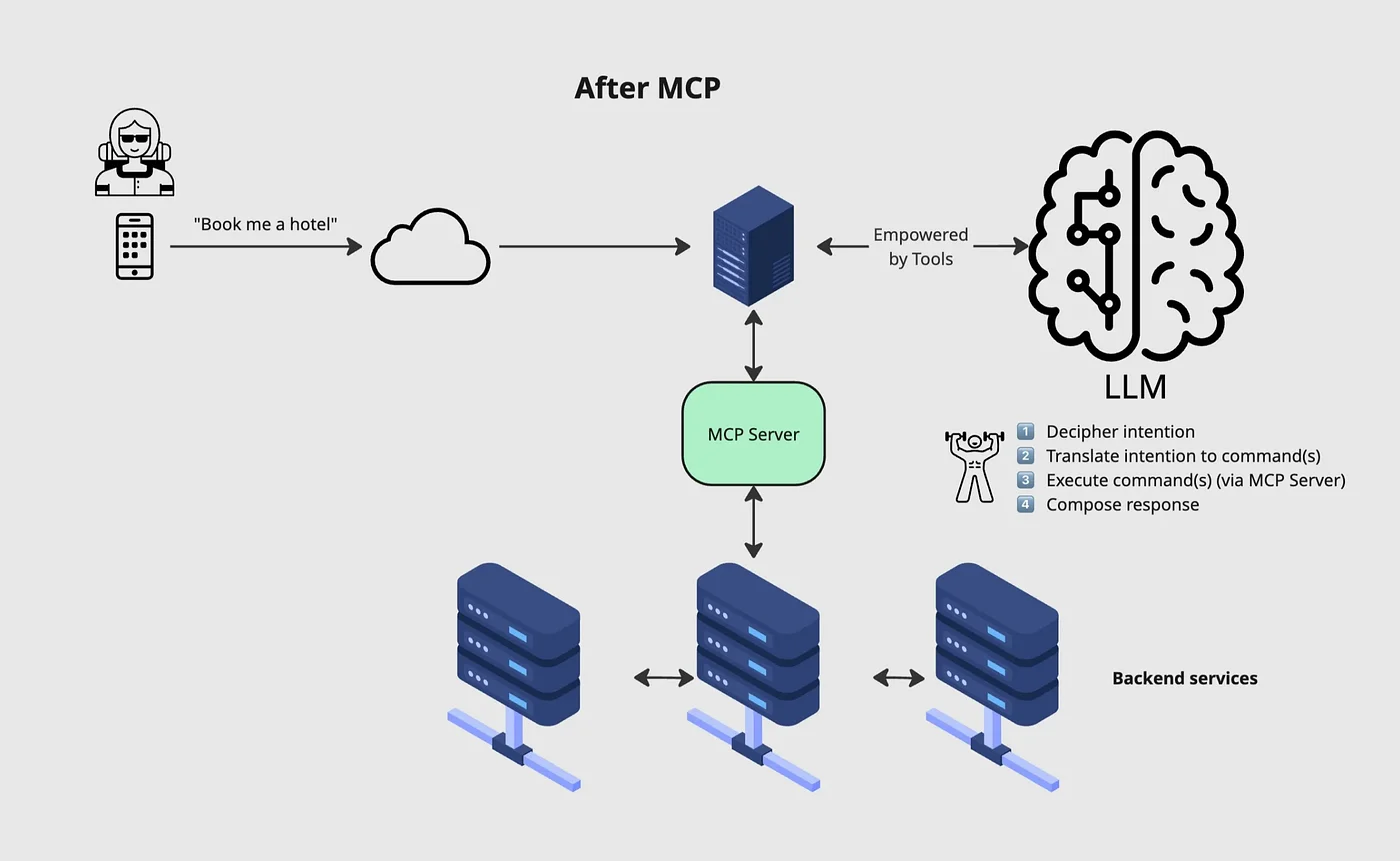
The modern agentic architecture (shown in the cover diagram above) illustrates this vividly. An LLM empowered by tools receives a user intent, routes through an MCP server4, and produces effects on backend services. Each arrow in that diagram is a decision point — and each decision point is an opportunity for behavioral measurement. But that measurement only becomes trust infrastructure when it is structured, reproducible, and anchored to the requirements of the specific deployment context.
The connection between observability and trust is direct: you cannot build justified trust in a system you cannot observe. This is why immutable evaluation audit trails are not a compliance checkbox — they are the substrate on which trust is constructed. When an agent makes a decision that affects a user, the ability to trace that decision back to the evaluation evidence that justified its deployment is not optional. It is what separates responsible deployment from a bet.
"Evaluation without auditability is opinion. Auditability without evaluation is logging. The combination is the foundation of operational trust."
7.How We Approach This at RecruitBase
AgentFit emerged from a direct encounter with the evaluation gap described above. RecruitBase started by building evaluation infrastructure for human hiring processes — structured scoring, multi-dimensional fit assessment, behavioral profiling, audit trails. What we found was that the hard problems in human evaluation and AI agent evaluation are structurally the same: defining what "good" means in context, measuring against that definition consistently, and explaining the result in terms the decision-maker can act on.
The first design decision was to make evaluation context-explicit through Business Need Profiles (BNPs) — lightweight markdown files that express an organization's agent requirements in a structured, machine-readable format: which capabilities matter, how they should be weighted, what compliance standards apply, and at what task complexity you're operating. Every evaluation is anchored to a BNP, so scores are relative to your context, not an abstract standard.
The second was to assess agents across seven behavioral dimensions: Task Competence, Tool Use & Integration, Autonomy & Escalation, Safety & Alignment, Compliance & Auditability, Operational Performance, and Deployment Compatibility. Each dimension produces a 0–1 score with sub-metrics, weighted feedback, and pass/fail thresholds — all anchored to the BNP. The dimensions were derived from a survey of production failure modes in agentic systems, and are designed to be exhaustive across the behavioral surface area that matters for deployment decisions.
The third was to add an interpretability layer on top of scoring. Raw scores tell you what — the LLM sees the entire calculation trail, the BNP context, every sub-metric and its weight contribution, and returns natural-language explanations grounded in your requirements. This closes the gap between "the agent scored 0.74" and "here is specifically why, anchored to your compliance requirements, with prioritized recommendations."5 The explanations are arithmetically grounded — the LLM is given the exact calculation trail, not asked to summarize a score, so its output is verifiable, not hallucinated.
We chose to open-source AgentFit under Apache 2.0 for two reasons. First, the problem of agent evaluation is one the whole industry needs to solve together — proprietary solutions fragment the evaluation landscape and make cross-provider comparison harder, not easier. Second, the organizations most at risk from inadequate agent evaluation are often the ones that can't afford a commercial platform. Making the framework free ensures that the barrier to Level 3 maturity is capability, not budget.
8.Conclusion
The deployment moment for AI agents is now. That is not a prediction — it is a description of what is already happening across industries. The question is not whether organizations will deploy agents, but whether they will do so with the evaluation infrastructure that makes deployment responsible rather than reckless.
The evaluation gap is real, and it is structural. Model benchmarks do not answer agent fitness questions. Framework-native tools do not support cross-provider comparison. Manual review does not scale. The industry needs a shared vocabulary for agent evaluation — one grounded in business context, producing reproducible and auditable results, with interpretability that makes scores actionable.
Operational trust maturity for autonomous systems is not a distant aspiration. It is achievable today with the right tooling. But it requires treating evaluation as a first-class engineering concern, not an afterthought. The organizations that build that infrastructure now will be the ones that can move fast on agents and demonstrate that they did so responsibly. That combination — speed and defensibility — is the actual competitive advantage.
We're building the infrastructure to make that possible. We'd welcome your contributions, your critique, and your use cases.
Ref.References
- 1El Filali, A., & Bedar, I. (2025). Towards More Standardized AI Evaluation: From Models to Agents. arXiv preprint. Retrieved from arxiv.org/abs/2503.14737
- 2CMMI Institute. (2018). CMMI for Development, Version 2.0. Carnegie Mellon University Software Engineering Institute.
- 3OpenTelemetry Authors. (2024). OpenTelemetry Specification. CNCF. Retrieved from opentelemetry.io/docs/specs/otel
- 4Anthropic. (2024). Model Context Protocol (MCP) Specification. Retrieved from modelcontextprotocol.io
- 5RecruitBase. (2025). AgentFit: Agent Evaluation and Interpretability Framework (v0.2.0) [Computer software]. Apache License 2.0. Retrieved from github.com/RecruitBase/agentfit